
二进制部署Prometheus Alertmanager Grafana监控Linux主机并配置微信邮件告警
Prometheus 概述
SoundCloud 的官方博客中可以找到一篇关于他们为什么需要新开发一个监控系统的文章 Prometheus: Monitoring at SoundCloud,在这篇文章中,他们介绍到,他们需要的监控系统必须满足下面四个特性:
- A multi-dimensional data model, so that data can be sliced and diced at will, along dimensions like instance, service, endpoint, and method.
- Operational simplicity, so that you can spin up a monitoring server where and when you want, even on your local workstation, without setting up a distributed storage backend or reconfiguring the world.
- Scalable data collection and decentralized architecture, so that you can reliably monitor the many instances of your services, and independent teams can set up independent monitoring servers.
- Finally, a powerful query language that leverages the data model for meaningful alerting (including easy silencing) and graphing (for dashboards and for ad-hoc exploration).
简单来说,就是下面四个特性:
- 多维度数据模型
- 方便的部署和维护
- 灵活的数据采集
- 强大的查询语言
Prometheus 数据采集方式也非常灵活。要采集目标的监控数据,首先需要在目标处安装数据采集组件,这被称之为 Exporter,它会在目标处收集监控数据,并暴露出一个 HTTP 接口供 Prometheus 查询,Prometheus 通过 Pull 的方式来采集数据,这和传统的 Push 模式不同。不过 Prometheus 也提供了一种方式来支持 Push 模式,你可以将你的数据推送到 Push Gateway,Prometheus 通过 Pull 的方式从 Push Gateway 获取数据。目前的 Exporter 已经可以采集绝大多数的第三方数据,比如 Docker、HAProxy、StatsD、JMX 等等,官网有一份 Exporter 的列表。除了这四大特性,随着 Prometheus 的不断发展,开始支持越来越多的高级特性,比如:服务发现,更丰富的图表展示,使用外部存储,强大的告警规则和多样的通知方式。下图是 Prometheus 的整体架构图
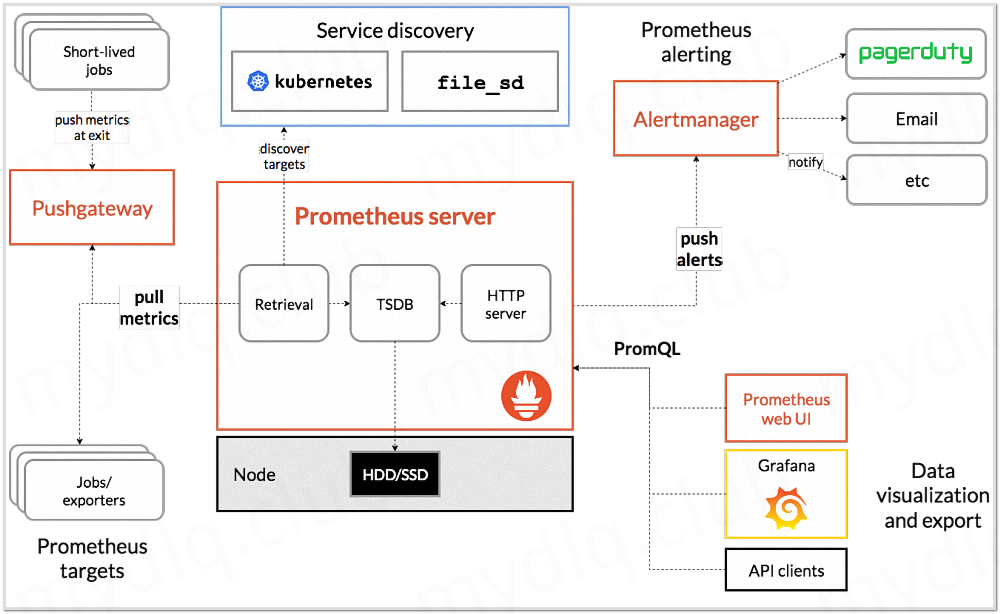
从上图可以看出,Prometheus 生态系统包含了几个关键的组件:Prometheus server、Pushgateway、Alertmanager、Web UI 等,但是大多数组件都不是必需的,其中最核心的组件当然是 Prometheus server,它负责收集和存储指标数据,支持表达式查询,和告警的生成
部署架构图
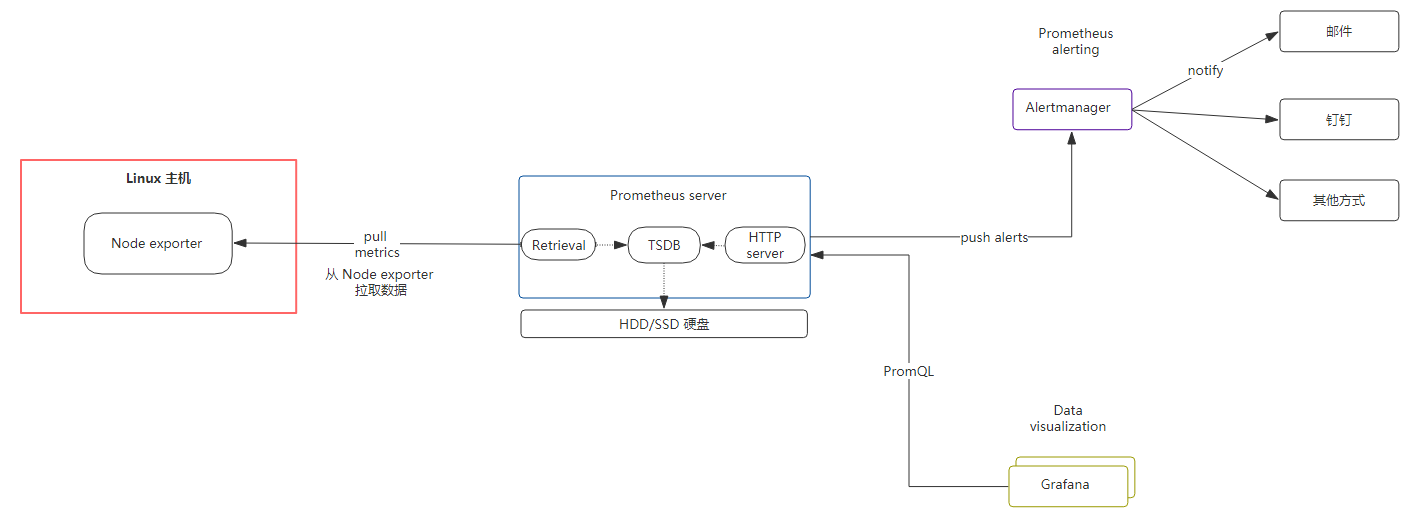
安装Prometheus Server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启Prometheus Server
下载并解压二进制安装包
通过prometheus的官网,下载的prometheus v2.35.0版本
[root@monitor ~]# wget https://github.com/prometheus/prometheus/releases/download/v2.35.0/prometheus-2.35.0.linux-amd64.tar.gz
[root@monitor ~]# tar -xf prometheus-2.35.0.linux-amd64.tar.gz
[root@monitor ~]# mv prometheus-2.35.0.linux-amd64 /usr/local/
[root@monitor ~]# ln -s /usr/local/prometheus-2.35.0.linux-amd64/ /usr/local/prometheus
配置说明
解压后当前目录会包含默认的Prometheus配置文件promethes.yml,下面配置文件做下简略的解析
# 全局配置
global:
scrape_interval: 15s # 设置抓取间隔,默认为1分钟
evaluation_interval: 15s #估算规则的默认周期,每15秒计算一次规则。默认1分钟
# scrape_timeout #默认抓取超时,默认为10s
# Alertmanager相关配置
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 规则文件列表,使用'evaluation_interval' 参数去抓取
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 抓取配置列表
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['10.22.4.8:9090']
创建prometheus的用户及数据存储目录
为了安全,使用普通用户来启动prometheus服务,作为一个时序型的数据库产品,prometheus的数据默认会存放在应用所在目录下,修改为 /data/prometheus下
[root@monitor ~]# useradd -s /sbin/nologin -M prometheus
[root@monitor ~]# mkdir /data/prometheus -p
#修改目录属主
[root@monitor ~]# chown -R prometheus:prometheus /usr/local/prometheus/
[root@monitor ~]# chown -R prometheus:prometheus /data/prometheus/
创建Systemd服务启动prometheus
prometheus的启动很简单,只需要直接启动解压目录的二进制文件prometheus即可,但是为了更加方便对prometheus进行管理,这里使用systemd来启停prometheus
[root@monitor ~]# vim /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus
Restart=on-failure
[Install]
WantedBy=multi-user.target
备注:在service文件里面,定义了启动的命令,定义了数据存储在/data/prometheus路径下,否则默认会在prometheus二进制的目录的data下
[root@monitor ~]# systemctl start prometheus
[root@monitor ~]# systemctl status prometheus
[root@monitor ~]# systemctl enable prometheus
访问prometheus
prometheus已经安装好了,prometheus启动后默认会启动9090端口,通过IP:9090访问
安装Grafana
prometheus能展示一些图表,但对比Grafana还是比较弱的。接下来我们安装Grafana服务,用来展示prometheus收集到的数据
下载并解压二进制包
本文下载的Grafana的版本为6.4.2,要下载其他的版本可以到Grafana的官网进行下载
[root@monitor ~]# wget https://dl.grafana.com/oss/release/grafana-6.4.2.linux-amd64.tar.gz
[root@monitor ~]# tar -zxvf grafana-6.4.2.linux-amd64.tar.gz
[root@monitor ~]# mv grafana-6.4.2 /usr/local/
[root@monitor ~]# ln -s /usr/local/grafana-6.4.2/ /usr/local/grafana
创建grafana用户及数据存放目录
[root@monitor ~]# useradd -s /sbin/nologin -M grafana
[root@monitor ~]# mkdir /data/grafana
[root@monitor ~]# chown -R grafana:grafana /usr/local/grafana/
[root@monitor ~]# chown -R grafana:grafana /data/grafana/
修改配置文件
修改 /usr/local/grafana/conf/defaults.ini 文件,配置为上面新建的数据目录
[root@monitor ~]# vim /usr/local/grafana/conf/defaults.ini
...
data = /data/grafana/data
logs = /data/grafana/log
plugins = /data/grafana/plugins
provisioning = /data/grafana/conf/provisioning
...
systemd管理启动grafana
[root@monitor ~]# vim /etc/systemd/system/grafana-server.service
[Unit]
Description=Grafana
After=network.target
[Service]
User=grafana
Group=grafana
Type=notify
ExecStart=/usr/local/grafana/bin/grafana-server -homepath /usr/local/grafana
Restart=on-failure
[Install]
WantedBy=multi-user.target
启停并设置开机启动
[root@monitor ~]# systemctl daemon-reload
[root@monitor ~]# systemctl start grafana-server.service
[root@monitor ~]# systemctl enable grafana-server.service
访问grafana
grafana-server会启动3000端口,IP:3000打开grafana页面,然后输入默认的账号密码 admin/admin登录

添加数据源
grafana虽然已经部署,但是这个时候还没有数据,没办法作图。把grafana和prometheus关联起来,也就是在grafana中添加添加数据源
在配置页面点击添加数据源,然后选择prometheus,输入prometheus服务的参数即可
添加自带的示例图表
按照上面的指导添加数据源之后,就可以针对这些数据来绘制图表了。grafana最人性化的一点就是拥有大量的图表模板,只需要导入模板即可,从而省去了大量的制作图表的时间,目前我们的prometheus还没有什么监控数据,只有prometheus本身的数据,在添加数据源的位置上,右边的选项有个Dashboards的菜单选项,我们点击进去,然后导入prometheus2.0.
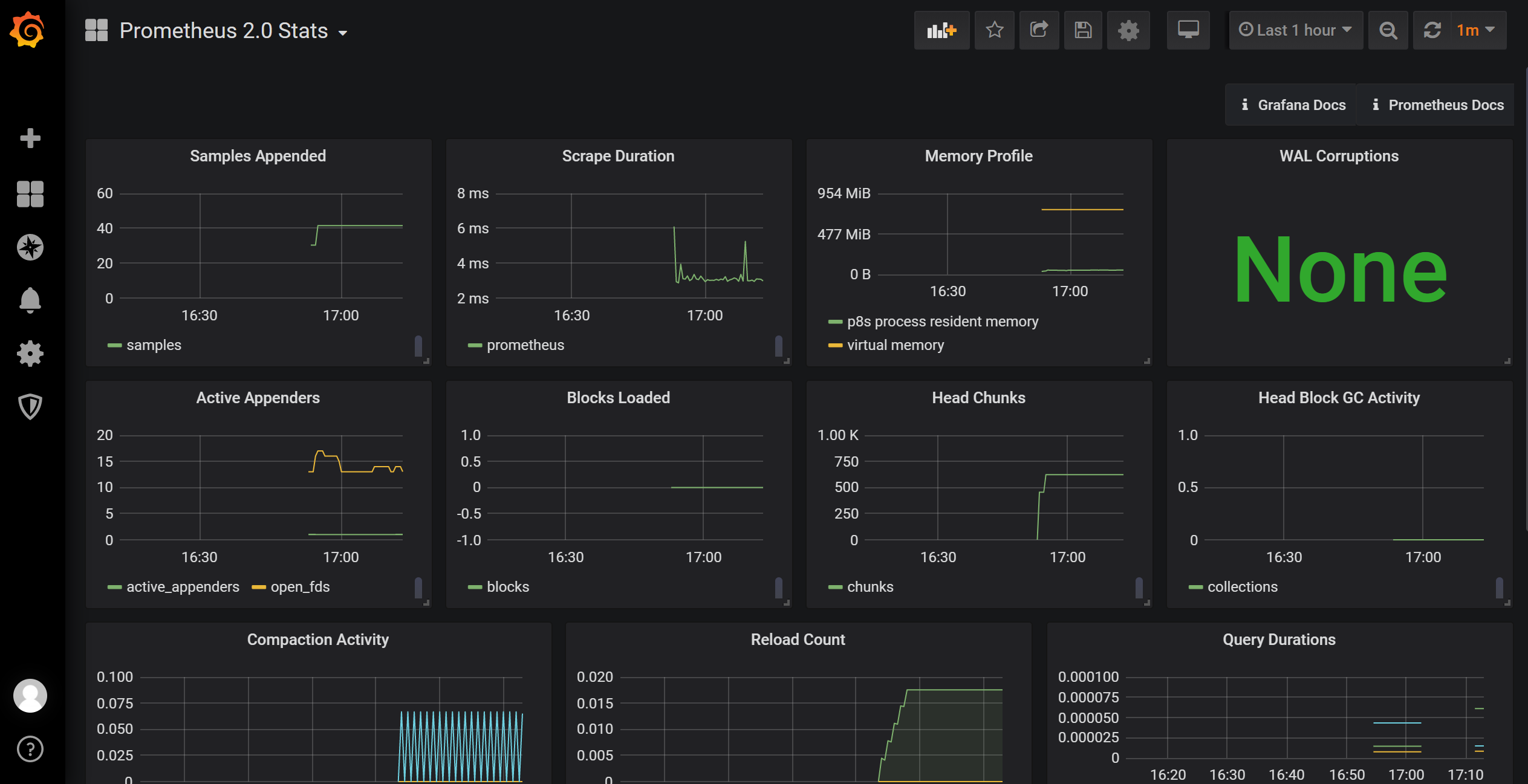
最后我们在左上角的位置上选择这个图表查看下,后续使用node-exporter来收集主机的性能信息,然后在grafana中展示
使用Node Exporter采集主机数据
与传统的监控zabbix来对比的话,prometheus就像是mysql,负责存储数据。只不过这是时序数据库而不是关系型的数据库。数据的收集还需要其他的客户端,在prometheus中叫做exporter。针对不同的服务,有各种各样的exporter,就好比zabbix的zabbix-agent一样。
为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息,可以使用Node Exporter,Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/获取最新的node exporter版本的二进制包
下载node exporte
这里下载的最新的1.3.1版本
[root@monitor ~]# wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
[root@monitor ~]# tar xzvf /root/node_exporter-1.3.1.linux-amd64.tar.gz -C /usr/local
[root@monitor ~]# mv /usr/local/node_exporter-1.3.1.linux-amd64 /usr/local/node_exporter
systemd管理启动node exporte
[root@monitor ~]# vim /etc/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
启停node exporte
[root@monitor ~]# systemctl start node_exporter.service
[root@monitor ~]# systemctl enable node_exporter.service
配置Prometheus收集node exporter数据
node exporter启动后也就是暴露了9100端口,并没有把数据传到prometheus,我们还需要在prometheus中配置,让prometheus去pull这个接口的数据,编辑prometheus.yml文件,增加后面4行(如部署再不同服务器修改成不同的job_name和对应的IP)
[root@monitor ~]# vim /usr/local/prometheus/prometheus.yml
...
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["10.22.4.8:9090"]
#采集node exporter监控数据
- job_name: 'node-application'
file_sd_configs:
- files: ['/usr/local/prometheus/node-application.yml']
refresh_interval: 5s
- job_name: 'node-prod'
file_sd_configs:
- files: ['/usr/local/prometheus/node-prod.yml']
refresh_interval: 5s
从上面配置可看出,不同的应用、不同环境尽量放置一个yml文件中,如应用/usr/local/prometheus/node-application.yml文件
[root@monitor ~]# vim /usr/local/prometheus/node-application.yml
- targets: ["10.22.4.8:9100"]
labels:
instance: monitor
- targets: ["10.22.4.9:9100"]
labels:
instance: Zabbix-proxy
...
可以根据分组来写不同的监控主机配置信息,然后重启prometheus,打开prometheus页面查看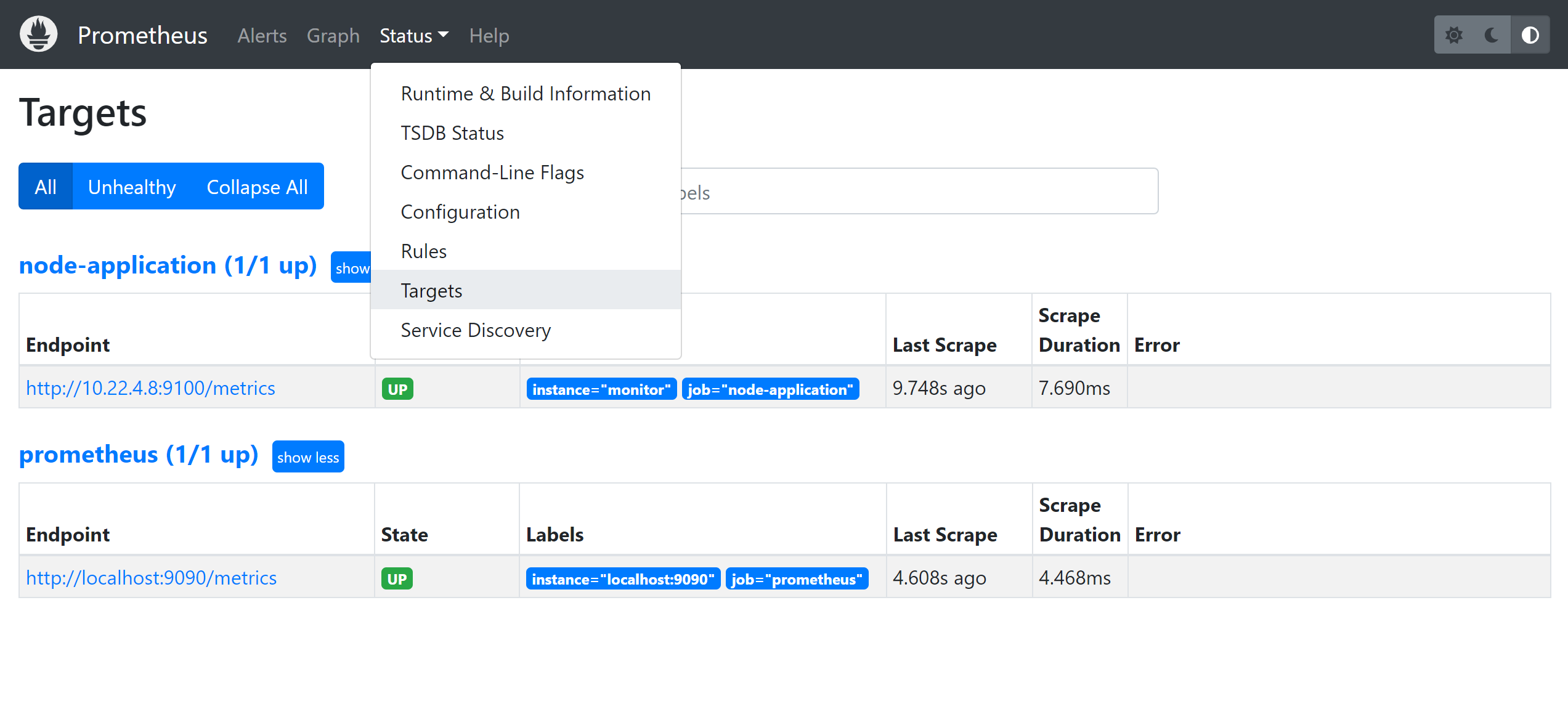
prometheus的web界面看到这个节点是up的状态了,接下来在grafana中添加对应的模板
导入grafana模板
导入界面输入模板的编号,这里使用的是9276号模板,如要使用其他的模板,grafana官网去查找https://grafana.com/grafana/dashboards
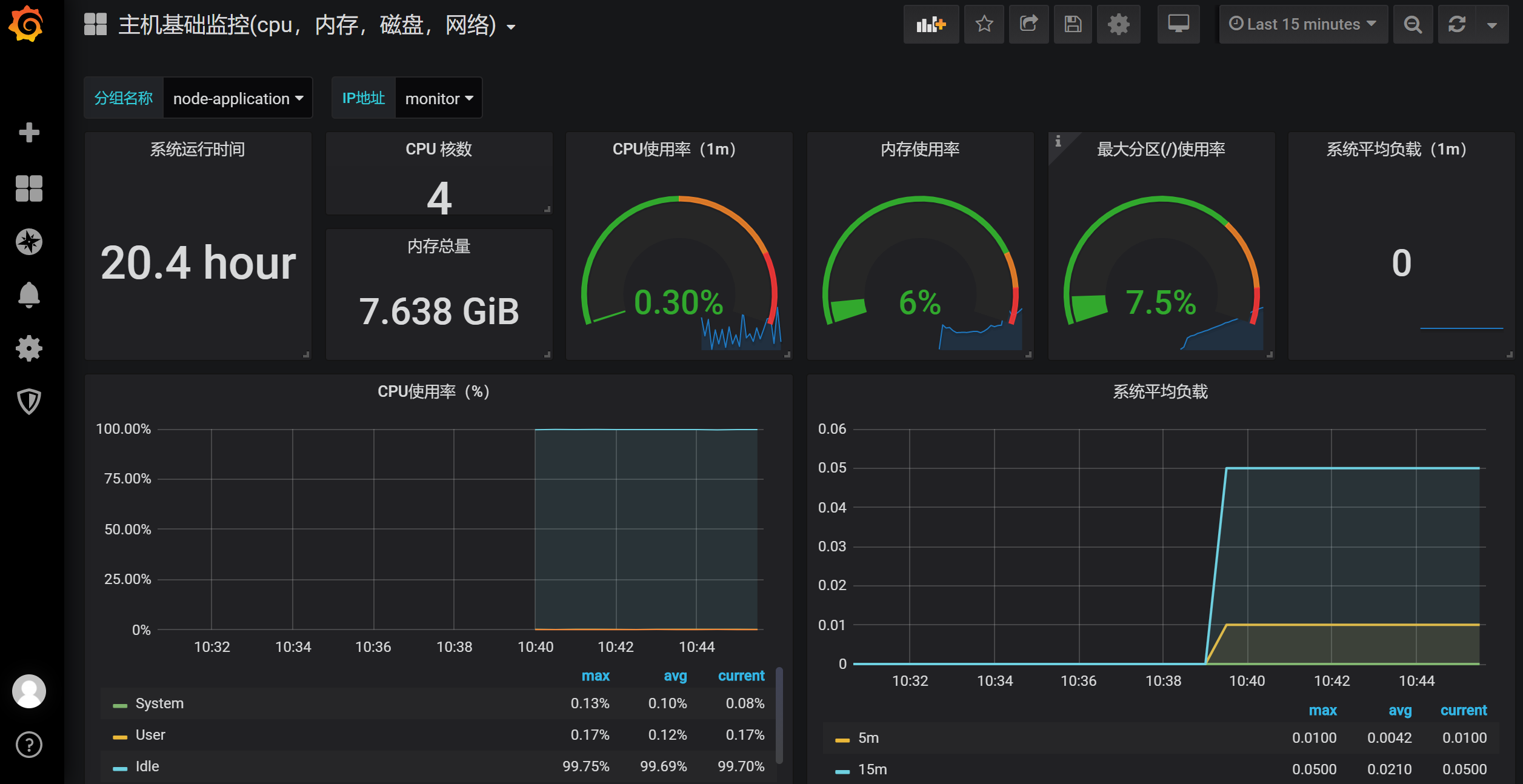
AlertManager安装
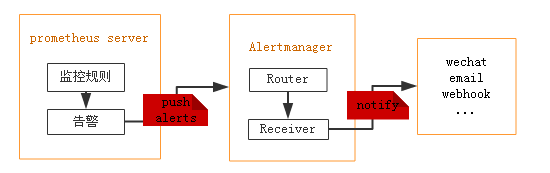
Prometheus 包含一个报警模块,就是我们的 AlertManager,Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组等,是一款前卫的告警通知系统
Alertmanager是一个独立的告警模块,接收Prometheus等客户端发来的警报,之后通过分组、删除重复等处理,并将它们通过路由发送给正确的接收器;告警方式可以按照不同的规则发送给不同的模块负责人,Alertmanager支持Email, Slack,等告警方式, 也可以通过webhook接入钉钉等IM工具
Prometheus发出告警时分为两个部分,Prometheus服务器按告警规则(rule_files配置块)将警报发送到Alertmanager(即告警规则是在Prometheus上定义的),然后由Alertmanager 来管理这些警报,包括去重(Deduplicating)、分组(Grouping)、沉默(silencing),抑制(inhibition),聚合(aggregation),最终通过电子邮件发出通知,对呼叫通知系统,以及即时通讯平台,将告警通知路由(route)给对应的联系人
设置警报和通知的主要步骤是
- 设置和配置 Alertmanager
- 配置Prometheus与Alertmanager对话
- 在Prometheus中创建警报规则
Alert的三种状态
pending:警报被激活,但是低于配置的持续时间。这里的持续时间即rule里的FOR字段设置的时间。改状态下不发送报警
firing:警报已被激活,而且超出设置的持续时间。该状态下发送报警
inactive:既不是pending也不是firing的时候状态变为inactive
prometheus触发一条告警的过程
prometheus—>触发阈值—>超出持续时间—>alertmanager—>分组|抑制|静默—>媒体类型—>邮件|钉钉|微信等
部署Alertmanager
二进制包下载解压后即可使用,官网地址:https://prometheus.io/download/,这里安装最新的版本
[root@monitor ~]# wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz
[root@monitor ~]# tar xf alertmanager-0.24.0.linux-amd64.tar.gz
[root@monitor ~]# mv alertmanager-0.24.0.linux-amd64 /usr/local/alertmanager
systemd管理alertmanager
[root@monitor ~]# vim /etc/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager
After=network-online.target
[Service]
Restart=on-failure
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
[Install]
WantedBy=multi-user.target
启停alertmanager
[root@monitor ~]# systemctl daemon-reload
[root@monitor ~]# systemctl start alertmanager
[root@monitor ~]# systemctl status alertmanager
访问alertmanager页面
alertmanager启动后直接访问IP:9093
alertmanager配置文件
[root@monitor ~]# vim /usr/local/alertmanager/alertmanager.yml
#global全局配置,主要配置告警方式,如邮件、webhook等
global:
resolve_timeout: 5m #超时,默认5min
smtp_smarthost: 'smtp.exmail.qq.com:25'
smtp_from: 'xxx.com'
smtp_auth_username: 'xxx.com'
smtp_auth_password: 'xxxxxxxx'
smtp_require_tls: false
smtp_hello: '10.22.4.8:9093' #alertmanager地址
templates: #告警模板(可定义多个)
- '/usr/local/alertmanager/template/*.tmpl'
#route:用来设置报警的分发策略。Prometheus的告警先是到达alertmanager的根路由(route),alertmanager的根路由不能包含任何匹配项,因为根路由是所有告警的入口点
#另外,根路由需要配置一个接收器(receiver),用来处理那些没有匹配到任何子路由的告警(如果没有配置子路由,则全部由根路由发送告警),即缺省
#接收器。告警进入到根route后开始遍历子route节点,如果匹配到,则将告警发送到该子route定义的receiver中,然后就停止匹配了。因为在route中
#continue默认为false,如果continue为true,则告警会继续进行后续子route匹配。如果当前告警仍匹配不到任何的子route,则该告警将从其上一级(
#匹配)route或者根route发出(按最后匹配到的规则发出邮件)。查看你的告警路由树,https://www.prometheus.io/webtools/alerting/routing-tree-editor/,
#将alertmanager.yml配置文件复制到对话框,然后点击"Draw Routing Tree"
route:
group_by: ['env','instance','type','group','job','alertname'] #用于分组聚合,对告警通知按标签(label)进行分组,将具有相同标签或相同告警名称(alertname)的告警通知聚合在一个组,然后作为一个通知发送。如果想完全禁用聚合,可以设置为group_by: [...]
group_wait: 10s #当一个新的告警组被创建时,需要等待'group_wait'后才发送初始通知。这样可以确保在发送等待前能聚合更多具有相同标签的告警,最后合并为一个通知发送
group_interval: 2m #当第一次告警通知发出后,在新的评估周期内又收到了该分组最新的告警,则需等待'group_interval'时间后,开始发送为该组触发的新告警,可以简单理解为,group就相当于一个通道(channel)
repeat_interval: 10m #告警通知成功发送后,若问题一直未恢复,需再次重复发送的间隔(根据实际情况来调整)
receiver: 'email' #配置告警消息接收者,与下面配置的对应,例如常用的 email、wechat、slack、webhook 等消息通知方式。
routes: #子路由
- receiver: 'wechat'
match: #通过标签去匹配这次告警是否符合这个路由节点;也可以使用match_re进行正则匹配
severity: Disaster #标签severity为Disaster时满足条件使用wechat警报
continue: true #匹配到这个路由后是否继续匹配,默认是flase
receivers: #配置报警信息接收者信息
- name: 'email' #警报接收者名称
email_configs:
- to: 'xx@x.com' #接收警报的email(可引用模板文件中定义的变量),可定义多个
html: '{{ template "email.to.html" .}}' #发送邮件的内容(调用模板文件中的)
helo: 'alertmanager:9093' #alertmanager的地址
headers: { Subject: "Prometheus [Warning] 报警邮件" } #邮件标题,不设定使用默认的即可
send_resolved: true #故障恢复后通知
- name: 'wechat'
wechat_configs:
- corp_id: xxxxxxxx #企业信息
to_user: '@all' #发送给企业微信用户的ID,这里是所有人
agent_id: xxxxxx #企业微信AgentId
api_secret: xxxxxxxxxxxx #企业微信Secret
message: '{{ template "wechat.default.message" .}}' #发送内容(调用模板里面的微信模板)
send_resolved: true #故障恢复后通知
inhibit_rules: #抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
检查配置
[root@monitor ~]# /usr/local/alertmanager/amtool check-config /usr/local/alertmanager/alertmanager.yml
Checking '/usr/local/alertmanager/alertmanager.yml' SUCCESS
Found:
- global config
- route
- 1 inhibit rules
- 2 receivers
- 1 templates
SUCCESS
告警模板配置
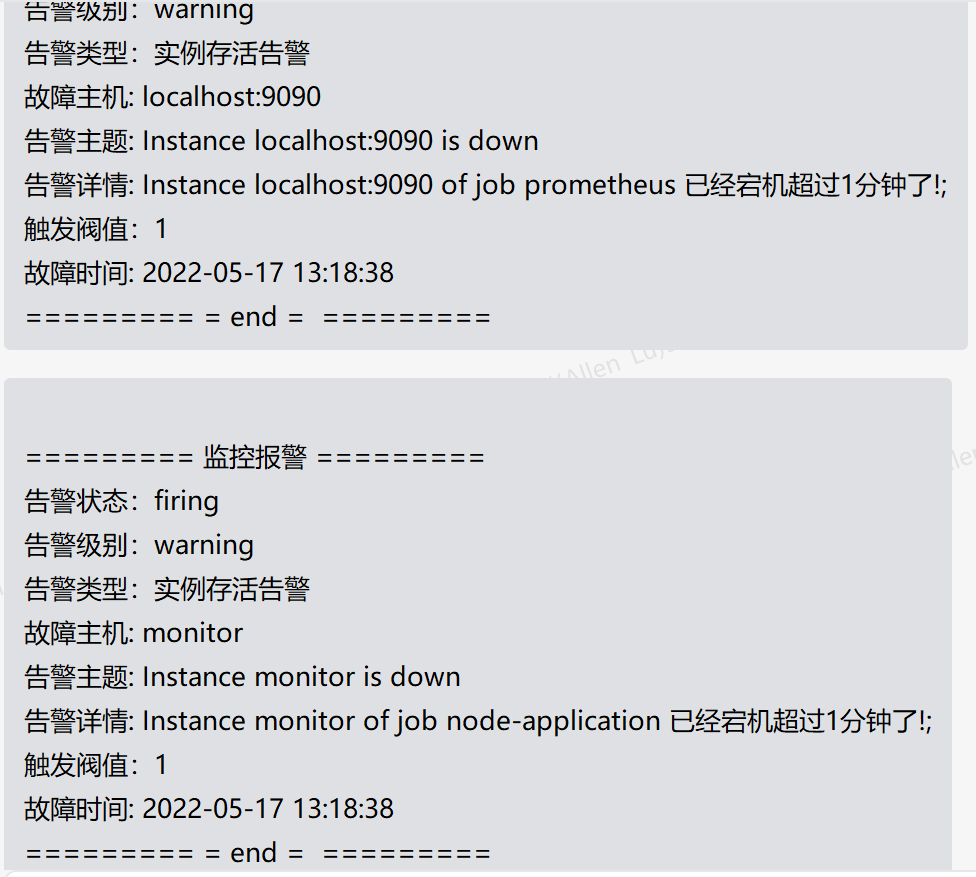
微信模板
[root@monitor ~]# vim /usr/local/alertmanager/template/wechat.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 告警恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
邮件模板
[root@monitor ~]# vim /usr/local/alertmanager/template/email.tmpl
{{ define "email.from" }}xxx.com{{ end }}
{{ define "email.to" }}xxx.com{{ end }}
{{ define "email.to.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{{ end }}{{ end -}}
{{- end }}
上边模板文件配置了 email.from、email.to、email.to.html 三种模板变量,可以在 alertmanager.yml 文件中直接配置引用。这里 email.to.html 就是要发送的邮件内容,支持 Html 和 Text 格式,这里为了显示好看,采用 Html 格式简单显示信息。下边 {{ range .Alerts }} 是个循环语法,用于循环获取匹配的 Alerts 的信息
Prometheus集成alertmanager
Prometheus配置文件配置alertmanager
[root@monitor ~]# vim /usr/local/prometheus/prometheus.yml
...
alerting:
alertmanagers:
- static_configs:
- targets: ['10.22.4.8:9093']
# - alertmanager:9093
...
配置prometheus告警规则
prometheus.yml中加入告警规则配置文件
[root@monitor ~]# cat /usr/local/prometheus/prometheus.yml
...
rule_files:
- "rules/node_status.yml" #可根据不同告警规则分成不同组
# - "rules/first_rules.yml"
# - "rules/second_rules.yml"
...
配置告警规则文件:node_status.yml
[root@monitor ~]# vim /usr/local/prometheus/rules/node_status.yml
groups:
- name: 实例存活告警规则
rules:
- alert: 实例存活告警
expr: up{job="prometheus"} == 0 or up{job="node-application"} == 0 #这里的job和配置文件里面的job_name对应
for: 1m
labels:
user: prometheus
severity: Disaster
annotations:
summary: "Instance {{ $labels.instance }} is down"
description: "{{ $labels.instance }} of {{ $labels.job }} 客户端在1分钟内连接失败"
value: "{{ $value }}"
- name: 内存告警规则
rules:
- alert: "内存使用率告警"
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
user: prometheus
severity: Disaster
annotations:
summary: "{{$labels.alertname}} 内存报警"
description: "{{ $labels.alertname }} 内存资源利用率大于80%!(当前值: {{ $value }}%)"
value: "{{ $value }}"
- name: CPU报警规则
rules:
- alert: CPU使用率告警
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 80
for: 1m
labels:
user: prometheus
severity: Disaster
annotations:
summary: "{{$labels.alertname}} CPU报警"
description: "服务器: CPU使用超过80%!(当前值: {{ $value }}%)"
value: "{{ $value }}"
- name: 磁盘报警规则
rules:
- alert: 磁盘使用率告警
expr: (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 > 80
for: 1m
labels:
user: prometheus
severity: Disaster
annotations:
summary: "{{$labels.alertname}} 磁盘报警"
description: "服务器:{{$labels.alertname}},磁盘设备: 使用超过80%!(挂载点: {{ $labels.mountpoint }} 当前值: {{ $value }}%)"
value: "{{ $value }}"
重启prometheus和alertmanager
[root@monitor ~]# systemctl restart prometheus.service
[root@monitor ~]# systemctl restart alertmanager.service
本文为了测试,将0改为1,测试服务存活
{kind=link}
{kind=link}
 微信
微信
 支付宝
支付宝